PromethION sequencing in Antwerp in 2018
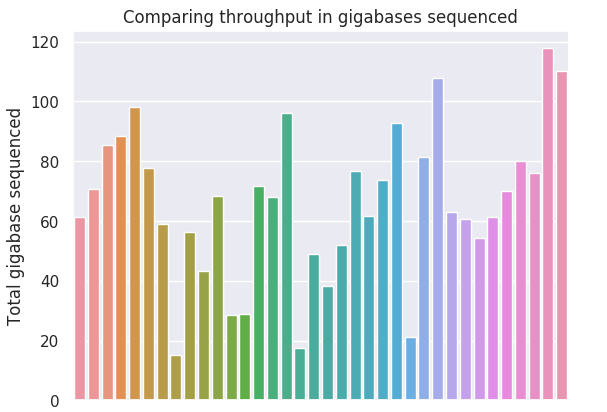
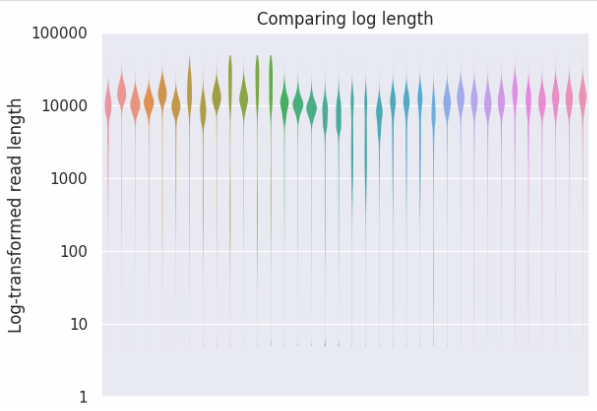
We started using PromethION about a year ago, but the good flow cells started arriving from February onwards. Below I have an overview of our runs so far, generated using NanoComp. I’ll blog more about these later if I have the time, but I’m finishing my PhD this month… The plots below show the yield in gigabase and the log transformed read length distribution per run, sorted by date of sequencing.
Our yield is quite variable, but the worst runs can be explained by bad input DNA quality. Garbage in, garbage out. Our best run so far was about 116Gbase. We haven’t been specifically optimizing our DNA extraction, as we are not interested in megabase reads which are without doubt interesting for assembly, but not necessarily that valuable for human genetics using alignment. We also see that shearing DNA to 10-20kb using MegaRuptor is highly beneficial for our yield - but this requires a more thorough investigation and optimization. We hope to get flongles soon for things like this… We also use BluePippin to remove short fragments from our library.
Finally, I’d like to remind you that we have made quite some PromethION human genome sequencing data from NA19240 available for download. Some of our results have also been described in two preprints:
Structural variants identified by Oxford Nanopore PromethION sequencing of the human genome