Trimming and filtering Oxford Nanopore sequencing reads
I recently wrote NanoFilt, a script for filtering and trimming of Oxford Nanopore sequencing data. The script reads from stdin, performs trimming and sends output to stdout. As such it can easily get integrated into your pipeline using pipes. All parameters are optional, so the reads are left unchanged when no flags are set.
Filtering can be done based on the minimal average quality of the read or on the minimal read length. After filtering the read can get cropped from the beginning or from the end for a specified number of bases. Installation The Python script can be installed with pip: pip install nanofilt The script is written for Python3, but might as well work for Python2.7 although I haven’t tested that. Usage NanoFilt [-h] [-q QUALITY] [-l LENGTH] [–headcrop HEADCROP] [–tailcrop TAILCROP]
optional arguments: -h, –help show this help message and exit -q, –quality QUALITY Filter on a minimum average read quality score -l, –length LENGTH Filter on a minimum read length –headcrop HEADCROP Trim n nucleotides from start of read –tailcrop TAILCROP Trim n nucleotides from end of read Example usage zcat reads.fastq.gz | NanoFilt -q 10 -l 500 –headcrop 50 | bwa mem -t 48 -x ont2d genome.fa - | samtools sort -O BAM -@24 -o alignment.bam - zcat reads.fastq.gz | NanoFilt -q 12 –headcrop 75 | gzip > trimmed-reads.fastq.gz Rationale My plots in a previous post suggested that trimming about 50 nucleotides from the beginning of a read can be beneficial since those show a biased content of nucleotide distribution and a substantially lower quality.
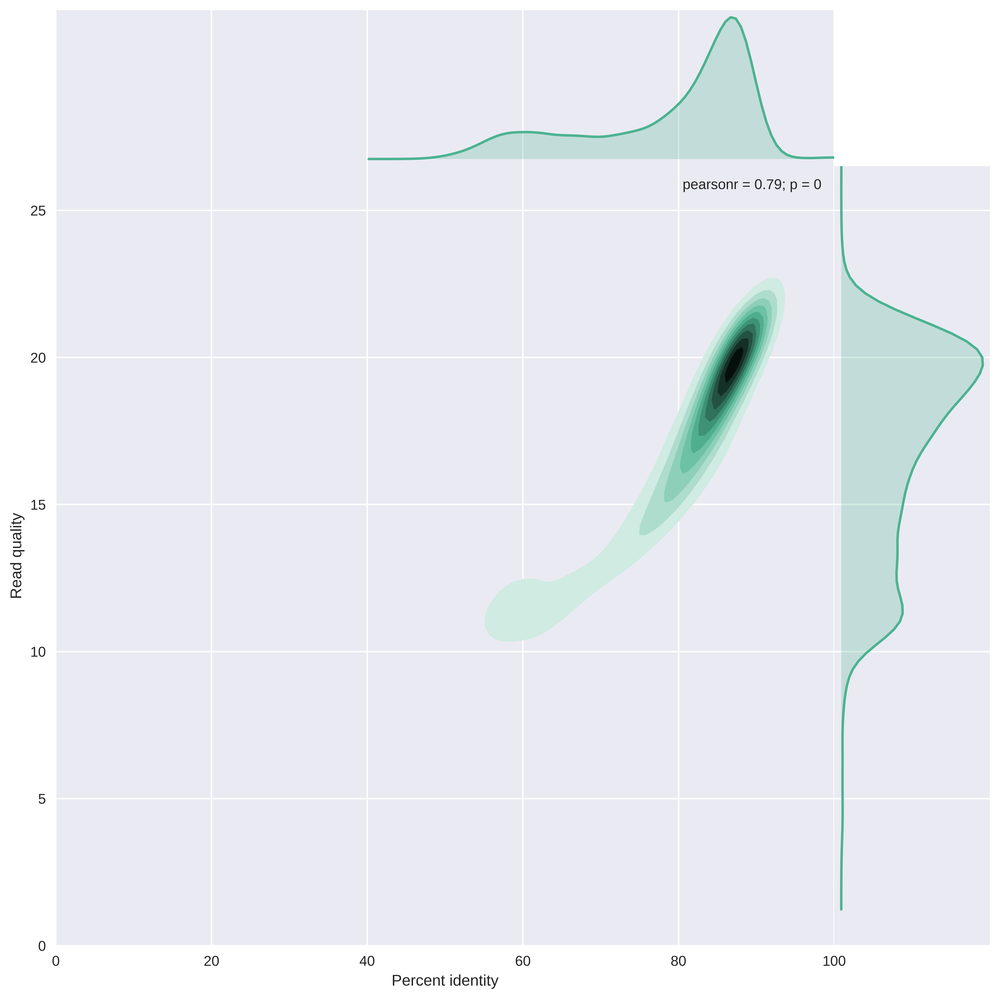
The plot below (from my NanoPlot gallery) shows the correlation between average read basecall quality and the edit distance to the reference genome scaled by read length (or the percent identity). This result suggests that reads with an average quality score below 13-15 have a striking lower percent identity. It may be important to remove those, depending on your application.
As always, I welcome all suggestions, feedback and feature requests!